Example 4: Image Multi-Class Classification (Conv Layers)¶
Compared to the previous example that uses only dense layers, this example uses convolutional layers to classify the same dataset.
Here is the complete code.
import torch
import torchga
import pygad
import numpy
def fitness_func(ga_instance, solution, sol_idx):
global data_inputs, data_outputs, torch_ga, model, loss_function
predictions = pygad.torchga.predict(model=model,
solution=solution,
data=data_inputs)
solution_fitness = 1.0 / (loss_function(predictions, data_outputs).detach().numpy() + 0.00000001)
return solution_fitness
def on_generation(ga_instance):
print(f"Generation = {ga_instance.generations_completed}")
print(f"Fitness = {ga_instance.best_solution()[1]}")
# Build the PyTorch model.
input_layer = torch.nn.Conv2d(in_channels=3, out_channels=5, kernel_size=7)
relu_layer1 = torch.nn.ReLU()
max_pool1 = torch.nn.MaxPool2d(kernel_size=5, stride=5)
conv_layer2 = torch.nn.Conv2d(in_channels=5, out_channels=3, kernel_size=3)
relu_layer2 = torch.nn.ReLU()
flatten_layer1 = torch.nn.Flatten()
# The value 768 is pre-computed by tracing the sizes of the layers' outputs.
dense_layer1 = torch.nn.Linear(in_features=768, out_features=15)
relu_layer3 = torch.nn.ReLU()
dense_layer2 = torch.nn.Linear(in_features=15, out_features=4)
output_layer = torch.nn.Softmax(1)
model = torch.nn.Sequential(input_layer,
relu_layer1,
max_pool1,
conv_layer2,
relu_layer2,
flatten_layer1,
dense_layer1,
relu_layer3,
dense_layer2,
output_layer)
# Create an instance of the pygad.torchga.TorchGA class to build the initial population.
torch_ga = torchga.TorchGA(model=model,
num_solutions=10)
loss_function = torch.nn.CrossEntropyLoss()
# Data inputs
data_inputs = torch.from_numpy(numpy.load("dataset_inputs.npy")).float()
data_inputs = data_inputs.reshape((data_inputs.shape[0], data_inputs.shape[3], data_inputs.shape[1], data_inputs.shape[2]))
# Data outputs
data_outputs = torch.from_numpy(numpy.load("dataset_outputs.npy")).long()
# Prepare the PyGAD parameters. Check the documentation for more information: https://pygad.readthedocs.io/en/latest/pygad.html#pygad-ga-class
num_generations = 200 # Number of generations.
num_parents_mating = 5 # Number of solutions to be selected as parents in the mating pool.
initial_population = torch_ga.population_weights # Initial population of network weights.
# Create an instance of the pygad.GA class
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=on_generation)
# Start the genetic algorithm evolution.
ga_instance.run()
# After the generations complete, a plot is shown that summarizes how the fitness values evolve over the generations.
ga_instance.plot_fitness(title="PyGAD & PyTorch - Iteration vs. Fitness", linewidth=4)
# Returning the details of the best solution.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print(f"Fitness value of the best solution = {solution_fitness}")
print(f"Index of the best solution : {solution_idx}")
# Make predictions based on the best solution.
predictions = pygad.torchga.predict(model=model,
solution=solution,
data=data_inputs)
# print("Predictions : \n", predictions)
# Calculate the crossentropy for the trained model.
print("Crossentropy : ", loss_function(predictions, data_outputs).detach().numpy())
# Calculate the classification accuracy for the trained model.
accuracy = torch.sum(torch.max(predictions, axis=1).indices == data_outputs) / len(data_outputs)
print("Accuracy : ", accuracy.detach().numpy())
Compared to the previous example, the only change is that the architecture uses convolutional and max-pooling layers. The shape of each input sample is 100x100x3.
input_layer = torch.nn.Conv2d(in_channels=3, out_channels=5, kernel_size=7)
relu_layer1 = torch.nn.ReLU()
max_pool1 = torch.nn.MaxPool2d(kernel_size=5, stride=5)
conv_layer2 = torch.nn.Conv2d(in_channels=5, out_channels=3, kernel_size=3)
relu_layer2 = torch.nn.ReLU()
flatten_layer1 = torch.nn.Flatten()
# The value 768 is pre-computed by tracing the sizes of the layers' outputs.
dense_layer1 = torch.nn.Linear(in_features=768, out_features=15)
relu_layer3 = torch.nn.ReLU()
dense_layer2 = torch.nn.Linear(in_features=15, out_features=4)
output_layer = torch.nn.Softmax(1)
model = torch.nn.Sequential(input_layer,
relu_layer1,
max_pool1,
conv_layer2,
relu_layer2,
flatten_layer1,
dense_layer1,
relu_layer3,
dense_layer2,
output_layer)
Prepare the Training Data¶
The data used in this example is available as 2 files:
dataset_inputs.npy: Data inputs. https://github.com/ahmedfgad/NumPyCNN/blob/master/dataset_inputs.npy
dataset_outputs.npy: Class labels. https://github.com/ahmedfgad/NumPyCNN/blob/master/dataset_outputs.npy
The data consists of 4 classes of images. The image shape is (100, 100, 3) and there are 20 images per class for a total of 80 training samples. For more information about the dataset, check the Reading the Data section of the pygad.cnn module.
Simply download these 2 files and read them according to the next code.
import numpy
data_inputs = numpy.load("dataset_inputs.npy")
data_outputs = numpy.load("dataset_outputs.npy")
The next figure shows how the fitness value changes.
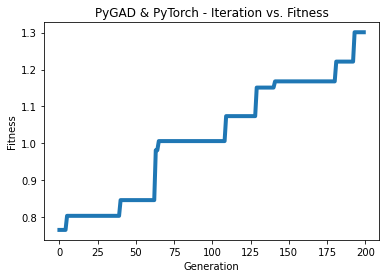
Here are some statistics about the trained model. The model accuracy is 97.5% after the 200 generations. Note that just running the code again may give different results.
Fitness value of the best solution = 1.3009520689219258
Index of the best solution : 0
Crossentropy : 0.7686678
Accuracy : 0.975