Example 3: Image Multi-Class Classification (Dense Layers)¶
Here is the code.
import tensorflow.keras
import pygad.kerasga
import numpy
import pygad
def fitness_func(ga_instance, solution, sol_idx):
global data_inputs, data_outputs, keras_ga, model
predictions = pygad.kerasga.predict(model=model,
solution=solution,
data=data_inputs)
cce = tensorflow.keras.losses.CategoricalCrossentropy()
solution_fitness = 1.0 / (cce(data_outputs, predictions).numpy() + 0.00000001)
return solution_fitness
def on_generation(ga_instance):
print(f"Generation = {ga_instance.generations_completed}")
print(f"Fitness = {ga_instance.best_solution()[1]}")
# Build the keras model using the functional API.
input_layer = tensorflow.keras.layers.Input(360)
dense_layer = tensorflow.keras.layers.Dense(50, activation="relu")(input_layer)
output_layer = tensorflow.keras.layers.Dense(4, activation="softmax")(dense_layer)
model = tensorflow.keras.Model(inputs=input_layer, outputs=output_layer)
# Create an instance of the pygad.kerasga.KerasGA class to build the initial population.
keras_ga = pygad.kerasga.KerasGA(model=model,
num_solutions=10)
# Data inputs
data_inputs = numpy.load("../data/dataset_features.npy")
# Data outputs
data_outputs = numpy.load("../data/outputs.npy")
data_outputs = tensorflow.keras.utils.to_categorical(data_outputs)
# Prepare the PyGAD parameters. Check the documentation for more information: https://pygad.readthedocs.io/en/latest/pygad.html#pygad-ga-class
num_generations = 100 # Number of generations.
num_parents_mating = 5 # Number of solutions to be selected as parents in the mating pool.
initial_population = keras_ga.population_weights # Initial population of network weights.
# Create an instance of the pygad.GA class
ga_instance = pygad.GA(num_generations=num_generations,
num_parents_mating=num_parents_mating,
initial_population=initial_population,
fitness_func=fitness_func,
on_generation=on_generation)
# Start the genetic algorithm evolution.
ga_instance.run()
# After the generations complete, a plot is shown that summarizes how the fitness values evolve over the generations.
ga_instance.plot_fitness(title="PyGAD & Keras - Iteration vs. Fitness", linewidth=4)
# Returning the details of the best solution.
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print(f"Fitness value of the best solution = {solution_fitness}")
print(f"Index of the best solution : {solution_idx}")
# Make predictions based on the best solution.
predictions = pygad.kerasga.predict(model=model,
solution=solution,
data=data_inputs)
# print(f"Predictions : \n{predictions}")
# Calculate the categorical crossentropy for the trained model.
cce = tensorflow.keras.losses.CategoricalCrossentropy()
print(f"Categorical Crossentropy : {cce(data_outputs, predictions).numpy()}")
# Calculate the classification accuracy for the trained model.
ca = tensorflow.keras.metrics.CategoricalAccuracy()
ca.update_state(data_outputs, predictions)
accuracy = ca.result().numpy()
print(f"Accuracy : {accuracy}")
Compared to the previous binary classification example, this example has multiple classes (4) and thus the loss is measured using categorical cross entropy.
cce = tensorflow.keras.losses.CategoricalCrossentropy()
solution_fitness = 1.0 / (cce(data_outputs, predictions).numpy() + 0.00000001)
Prepare the Training Data¶
Before building and training neural networks, the training data (input and output) needs to be prepared. The inputs and the outputs of the training data are NumPy arrays.
The data used in this example is available as 2 files:
dataset_features.npy: Data inputs. https://github.com/ahmedfgad/NumPyANN/blob/master/dataset_features.npy
outputs.npy: Class labels. https://github.com/ahmedfgad/NumPyANN/blob/master/outputs.npy
The data consists of 4 classes of images. The image shape is (100, 100, 3). The number of training samples is 1962. The feature vector extracted from each image has a length 360.
Simply download these 2 files and read them according to the next code. Note that the class labels are one-hot encoded using the tensorflow.keras.utils.to_categorical() function.
import numpy
data_inputs = numpy.load("../data/dataset_features.npy")
data_outputs = numpy.load("../data/outputs.npy")
data_outputs = tensorflow.keras.utils.to_categorical(data_outputs)
The next figure shows how the fitness value changes.
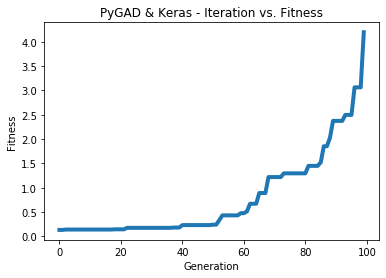
Here are some statistics about the trained model.
Fitness value of the best solution = 4.197464252185969
Index of the best solution : 0
Categorical Crossentropy : 0.23823906
Accuracy : 0.9852192